线性表(Linear List)
**1.线性表的定义** 
几个性质:
1.逻辑结构,每个元素都是一样的数据类型
2.每个数据元素占空间一样大
3.有次序
线性表的初始操作
总结:创销、增删改查
1.InitList(&L):初始化表。构造一个空的线性表L,分配内存空间
2.DestroyList(&L) :销毁操作。销毁线性表,并释放线性表L所占用的内存空间
3.ListInsert(&L,i,e):插入操作。在表L的第i个位置上插入指定元素e
4.ListDelete(&L,I,&e):删除操作。删除表L中第i个位置的元素,并用e
返回删除元素的值。
5.LocateElem(L,e):按值查找操作。在表L中查找具有给定关键字值的元素。
6.GetElem(L,i):按位查找操作。获取表L中第i个位置的元素的值
ps:什么时候要传入参数的引用“&"----对参数的修改结果需要”带回来“
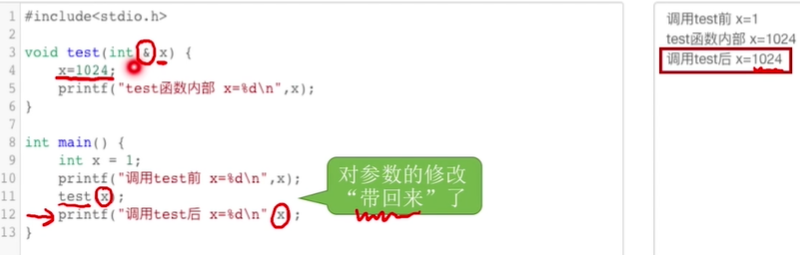
(调用带有&传引用的函数时,原来的值就会被改变,即”被带回来“

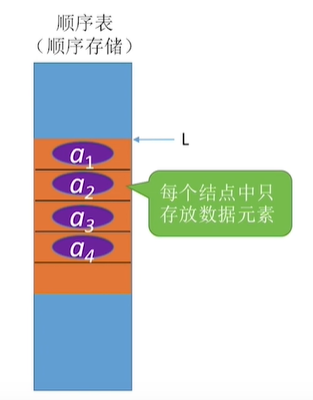
顺序表的定义
定义:用顺序存储的方式实现线性表
顺序存储:把逻辑上相邻的元素存储在物理位置上也相邻的存储单元中,元素之间的关系由存储单元的临接关系来体现
1.顺序表的实现——静态分配


所以我们就需要:
2.顺序表的实现——动态分配

Key:动态申请和释放内存空间:
C——malloc 、 free函数
顺序表的基本操作:插入(以静态分配为例子)
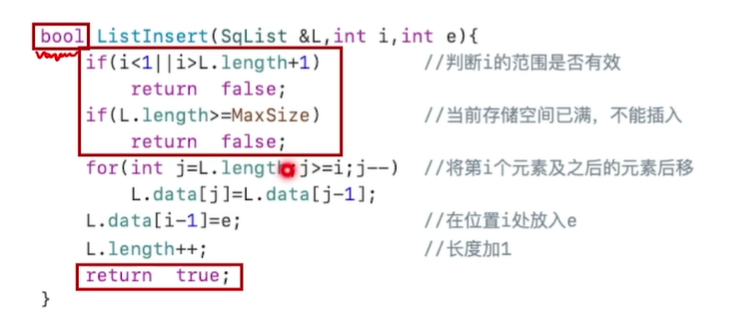
两个步骤:1. i 位置以及其后面的每个都往后移动一位(循环)
2.将第 i 个位置的值赋为e
ps:要给出一些边界判断以及合法性的错误反馈
时间复杂度:(省流:平均n/2,时间复杂度O(n))

顺序表的基本操作:删除

(第i个元素在顺序表里面是L.data[i-1])
1.为什么这里的e要加引用符号?
因为这样才能把参数e 带回来,加了引用符号后,函数里的e和main函数里的e在内存中
占同一个位置,后面输出e的时候才能把e输出出来,否则就还是原来初值的e。
时间复杂度:O(n)


顺序表的基本操作:查找
1.GetElem(L,i), 按位查找操作
1.1若为静态分配的顺序表,其实就直接返回L.data[i-1]

1.2若为动态分配的顺序表,一样
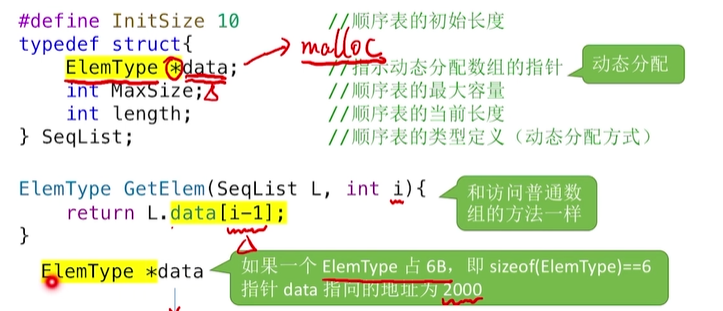
这俩的时间复杂度都为O(1)
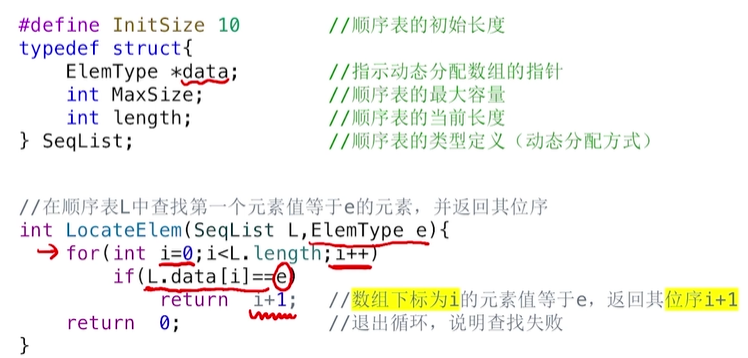
2.LocateElem(L,e),按值查找操作
3.顺序表的优缺点:

(随机存取,顺序存储,在物理上连续存放)
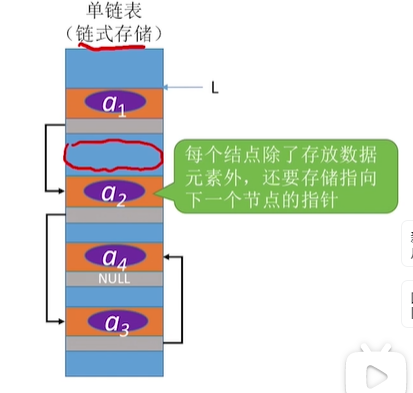
单链表
1.用代码定义一个单链表:
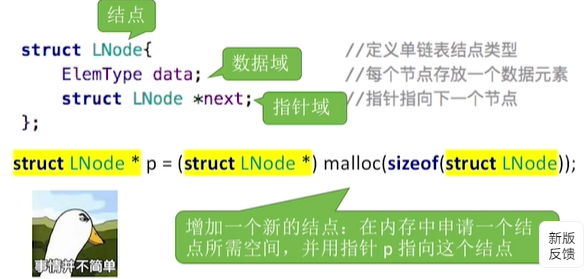
然鹅我们书里面是这样定义的,更加简洁:

强调是一个单链表:使用LinkList
强调是一个结点:使用LNode*
!!!LinkList等价于Lnode * !!!
2.初始化一个不带头结点的单链表

这里,要判断单链表是否为空,就用L==NULL是否为真
3.初始化带头结点的单链表:

用头结点指向的next域判断是否要成为头结点
L->next == NULL
大家都用带头结点的!头结点的下一个结点才开始存储数据
4.尾插法单链表按位序插入删除(带头结点的)
ListInsert(&L,I,e) :插入操作。在L的第i个位置上插入指定元素e。
其实也就是找到第i-1个结点,将新结点插入其后
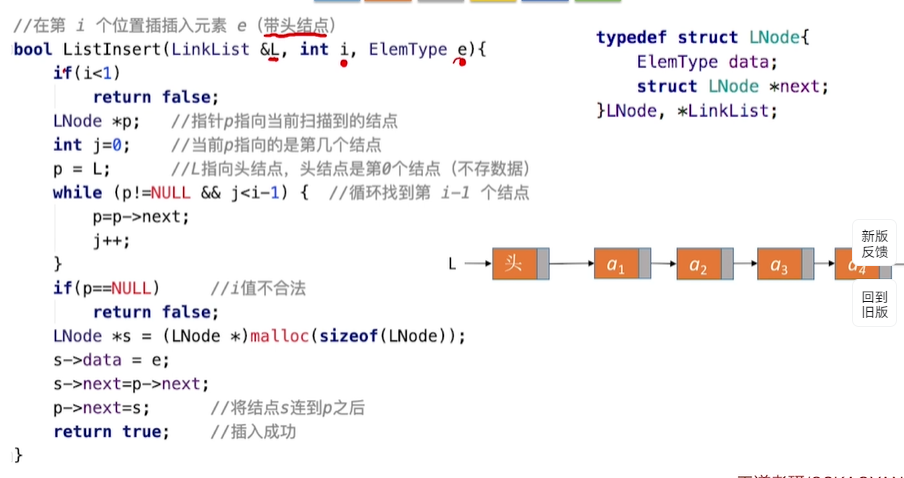
《注意倒二倒三行不能颠倒哦》
这个是尾插法
顺序:0.让p指针依次往后扫描 注意循环找到第i-1个结点
1.新创造一个结点s,给s申请内存
2.把e的值赋给s的数据域
3.p的next域赋值给s的next域
4.把结点s连到p的next上(其实3、4相当于在p后面生成了一个s。但是p是渣男,刚来就要走了)
5.返回true,表示创建成功
4.5 尾插法单链表按位序插入删除(不带头结点)

更麻烦,第一个结点的情况需要单独拿出来考虑,这个略 大家要注意考试两个都会考,但是一般默认带头结点的
上面这俩都是尾插法,时间复杂度都是O(n)
5.指定结点的前插操作:
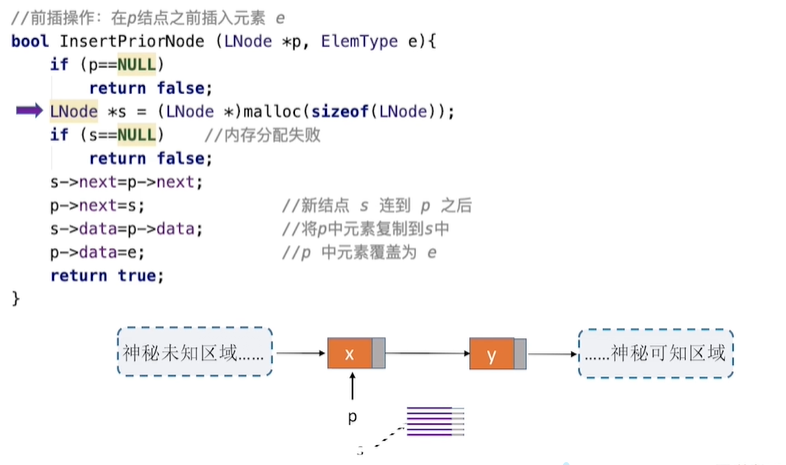
6.按位序删除(带头结点):
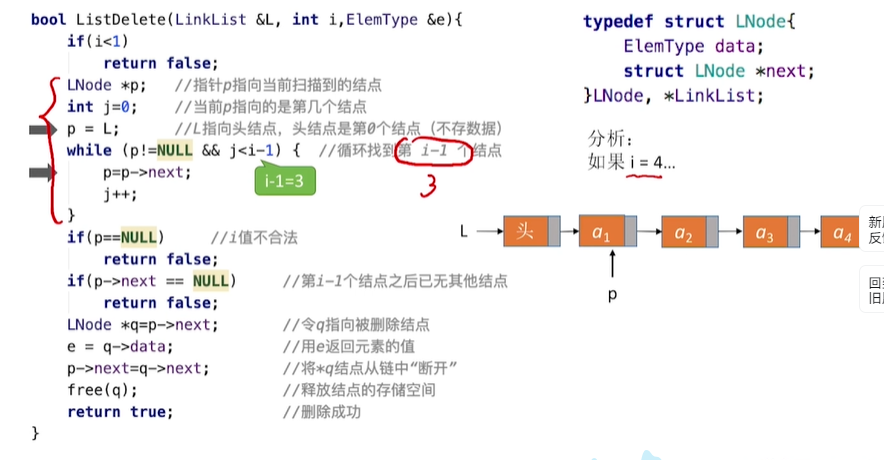
原理和插入差不多
主要是最后三点:
0.p在挨个搜索
1.让新定义的q指向被删除的结点的前一个结点的next域
2.用e返回q的data域
3.q的next域赋给p的next域(和插入相反)
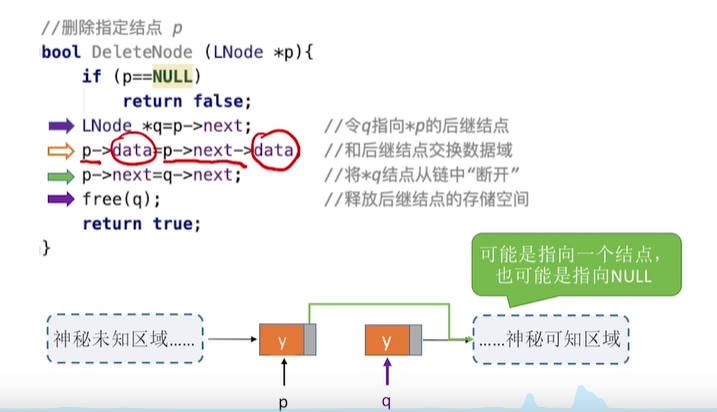
7.指定结点的删除:(带头结点)
8.按位查找
9.建立一个单链表(头插,尾插)
9.1 尾插法建立单链表

这里while里面的操作是这样的:
(s的意思是新申请的结点,r的意思是始终指向表尾的尾结点指针(这个重要))
1.给新结点s申请一个空间
2.把x的值赋给该新申请节点s的数据域
3.s的位置给r的next域
4.s成为新的表尾,r指向s结点
注意,最开始的L的next域可以不指向NULL(不会指向脏数据),但是肯定可以加上,也建议加上
9.2头插法建立单链表
去掉这一句就可能指向内存里的脏数据
注意:头插法可以用于链表的逆置!
顺序:
1.给新结点s申请空间
2.x的值赋给s的data域
3.L的next域赋给s的next域
4.s成为L的next域
单链表的优缺点:

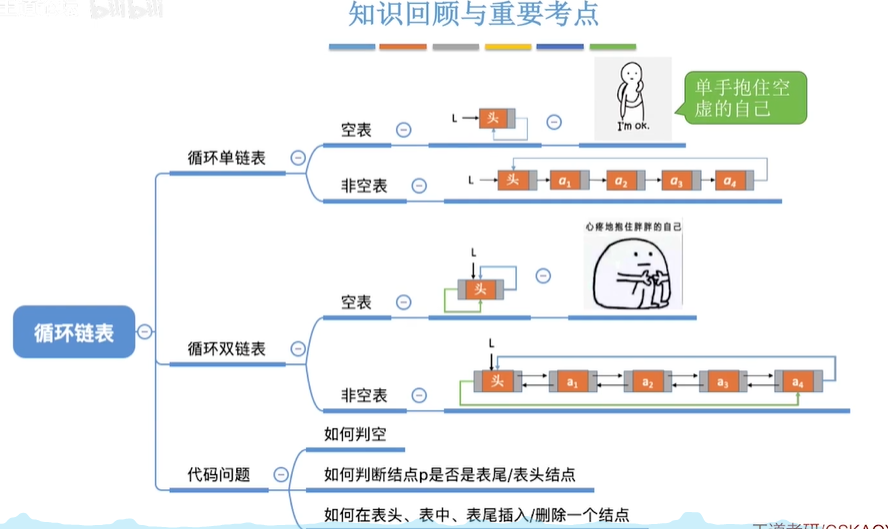
循环链表
一丢丢小小的差别:循环单链表的表尾结点的next指针指向头结点

另外一个不一样的点!
单链表从一个结点出发只能找到后续的各个节点
循环单链表从一个结点出发可以找到其他任何一个结点
(从头结点找到尾部,时间复杂度为O(n)
(从尾部找到头部,时间复杂度为O(1)
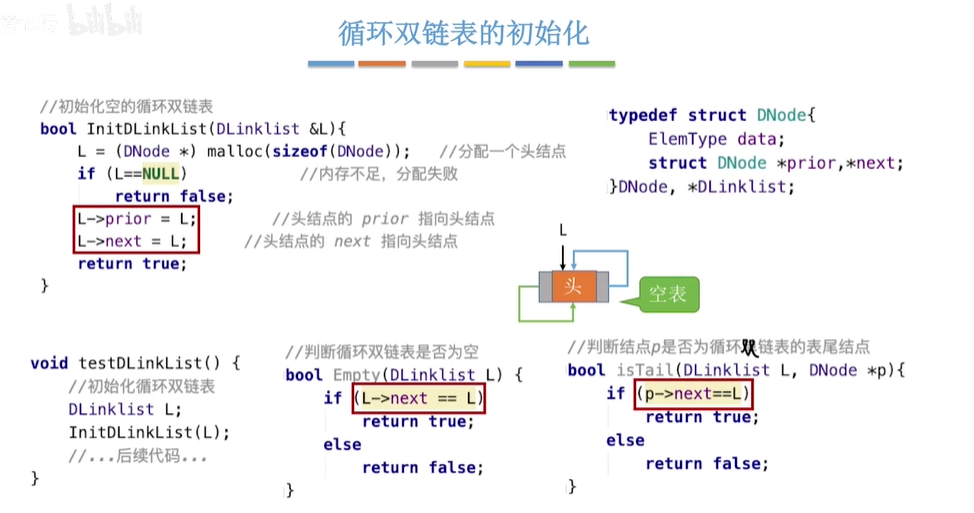
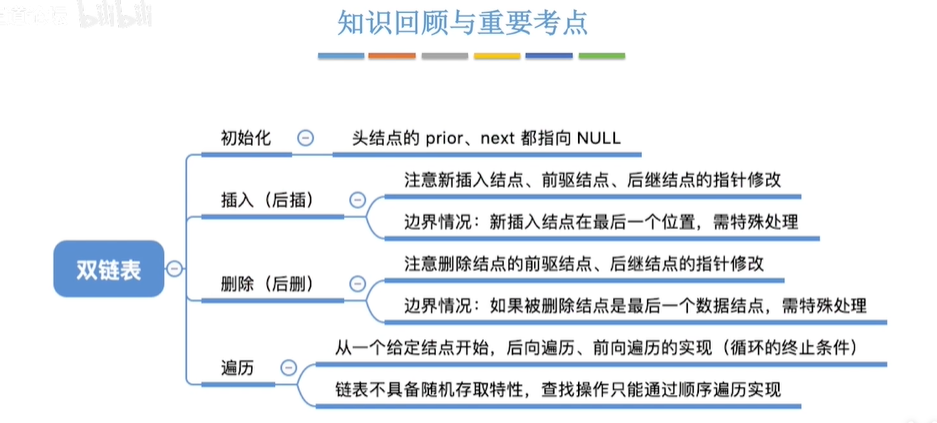
1.循环双链表的初始化;
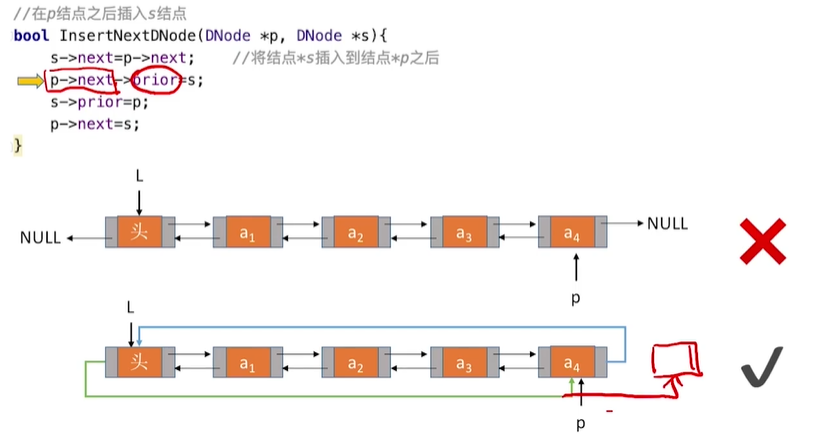
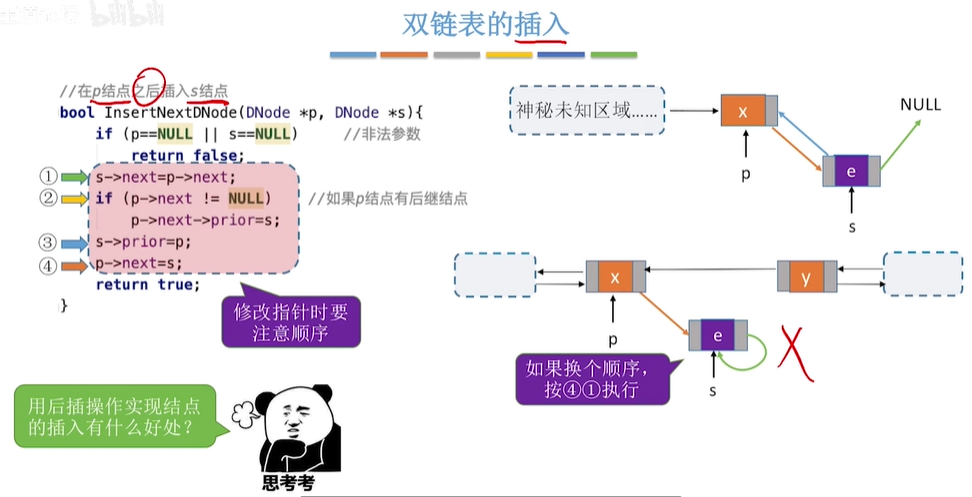
2.双链表的插入
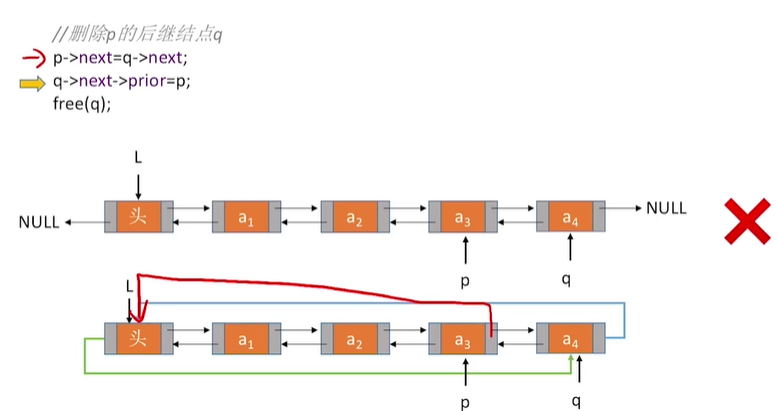
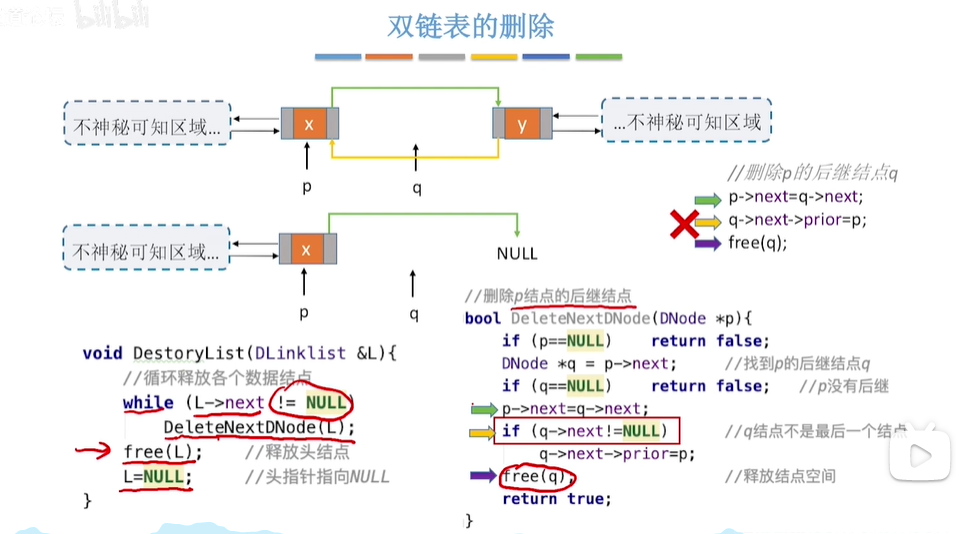
3.删除
总结:
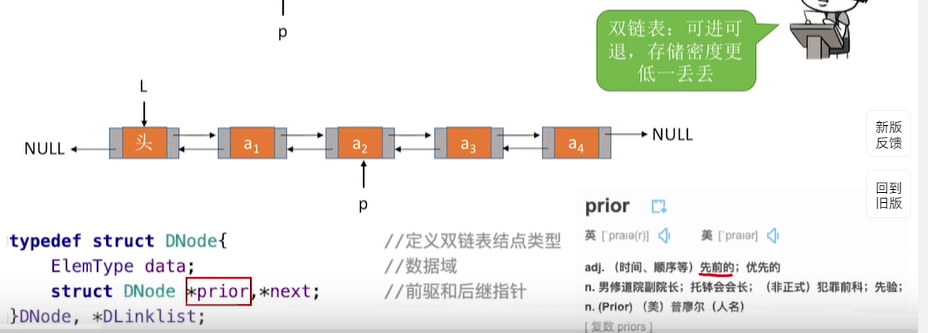
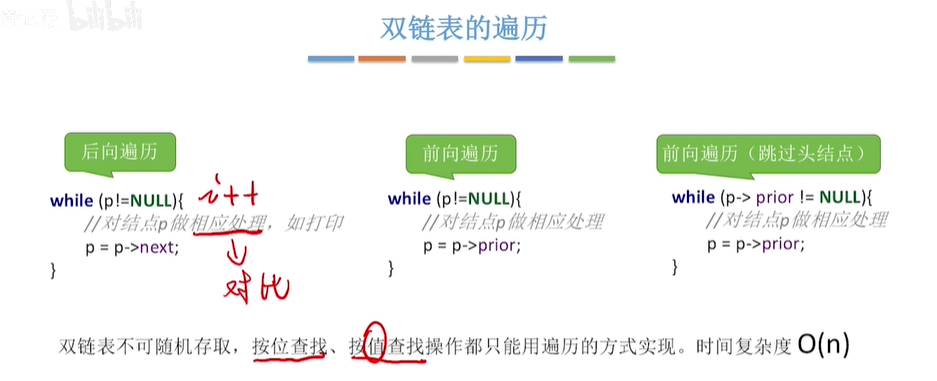
双链表

静态链表
顺序表和链表的比较
Round 1:逻辑结构
都属于线性表,都是数据结构
Round 2 :优缺点比较
顺序表:顺序存储
优点:支持随机存取,存储密度高
缺点:大片连续空间分配不容易,改变容量不方便
链表:链式存储
优点:离散的小空间分配方便,改变容量方便
缺点:不可随机存取,存储密度低
Round 3 :基本操作
创销、增删改查
创:
顺序表:1.需要预分配大片连续空间
2.若为静态分配,则容量不可改变
3.若为动态分配,容量可改变,但需要移动大量元素,时间代价高
链表:只需要分配一个头结点(也可以不要头结点,只声明一个头指针)方便后面拓展
显然链表灵活性优于顺序表
销:
顺序表:1.修改length=0(一个标志而已)
2.1静态分配:系统自动回收空间
2.2动态分配:需要手动free ,free(L.data)(malloc在堆区申请的空间)
链表:依次删除各个结点(free)
增删:
顺序表:插入/删除元素要将后续元素都后移、前移。
时间复杂度O(n),时间开销主要来自于移动元素。
(若数据元素很大,则移动的时间代价很高)
链表:插入删除元素只需要修改指针即可
时间复杂度O(n),时间开销主要来自于查找目标元素
(查找元素的时间代价更低)
所以链表的增删效率更高!
查:
顺序表:按位查找:O(1)
按值查找:O(n),若表内元素有序,可在O(log2n)时间内找到
链表:按位查找:O(n)
按值查找:O(n)
顺序表的效率更高!
总结:

